Tana Workspace Organization

A week ago, we had an amazing Tana JAM (community meetup) on Tana Decluttering. There we focused on strategies & best practices for Tana Workspace Organization.
In this article, I'll go through key insights from our conversation (and there were some real 💎).
There were three key questions that shaped our conversation:
- Where should I store things in Tana?
- When should you reuse fields?
- How can you effectively navigate the Tana schema?
Let's unpack them all!
Where to store things?
The big question for many Tana users: Does it matter where the original node lives?
The answer is not as straightforward as you might think.
Tana builds on a knowledge graph where information lives as a network. In a graph, nodes are linked by logical relationships.
Individual pieces of information [nodes] are linked by their logical relationships. So their physical location is secondary.
Connections unlock efficient information retrieval.
Example
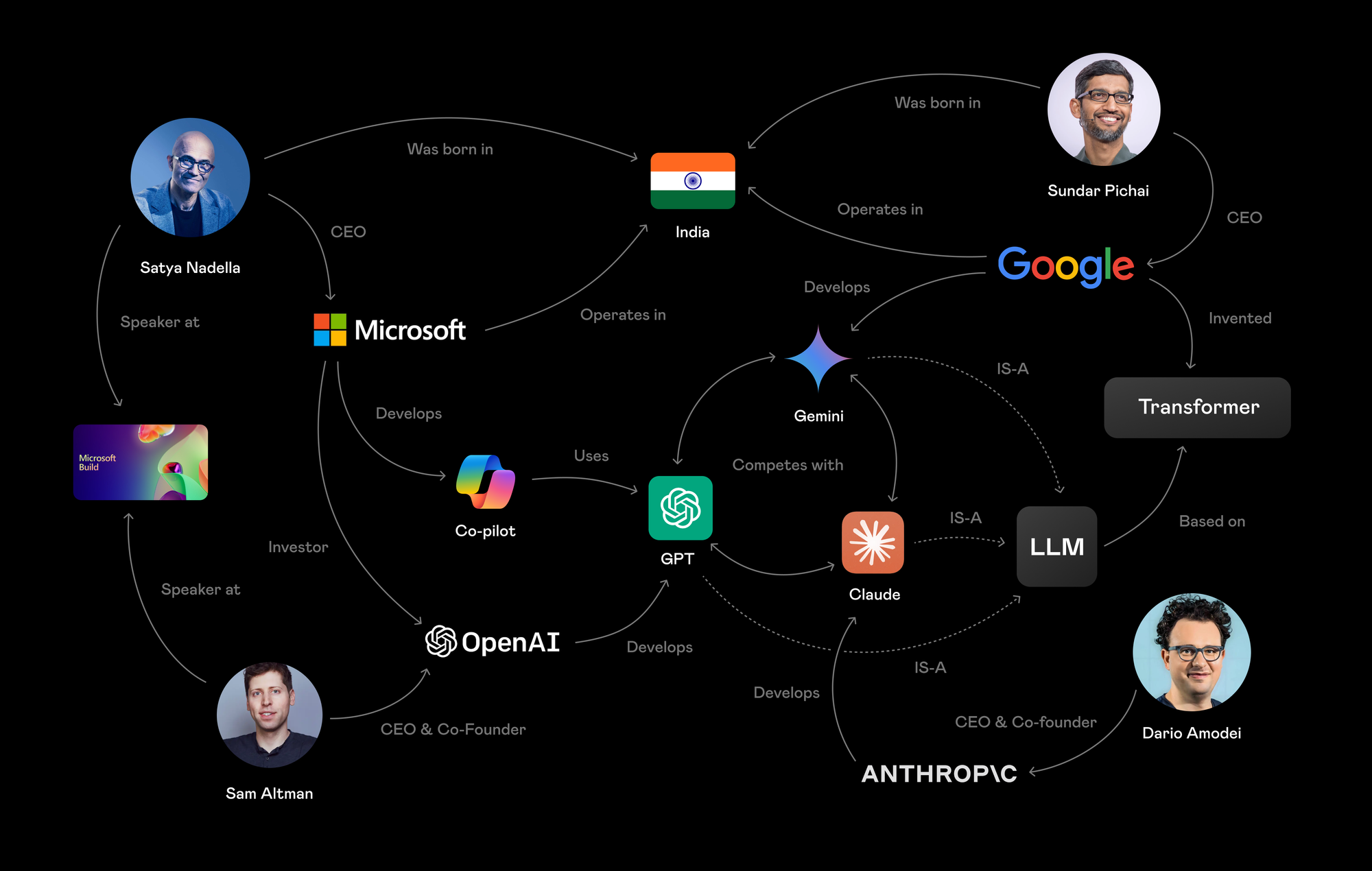
In this knowledge graph you will be able to find GPT via several relations.
First-order Connections:
- Developed by Open AI
- Used in Microsoft Co-pilot
- Competes with Gemini AND/OR Claude
- Is a Large Language Model
Higher-order connections (one of options):
- Large Language Models that are built by companies in which Microsoft invested
To truly master Tana, you need to embrace this concept of interconnected nodes.
Supertags, fields, and references are the tools you use to define those logical links between nodes, creating a web of knowledge.
If you use them consistently, you'll be able to find any information, no matter where it is located.
Yet, the physical placement of your nodes still matters for several reasons.
Fei-Ling Tseng put it perfectly:
I have started using a bit more hierarchical organization in my own work because I like being able to click back to the previous context through the breadcrumbs. I find that to be a pretty effective way to navigate around, especially for knowledge or information that lends itself to being structured that way.
So location in Tana still can be a useful tool. Let's unpack it.
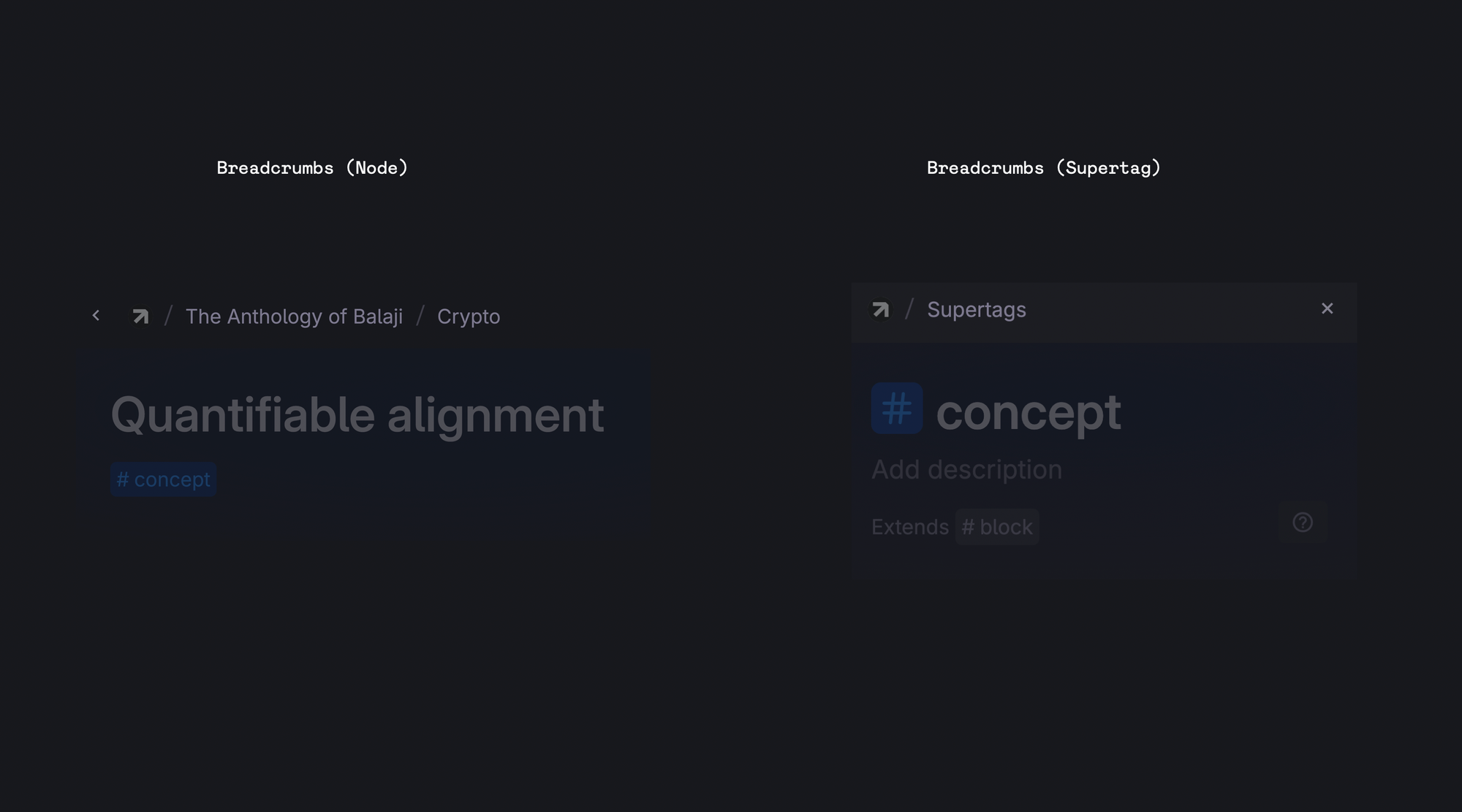
Breadcrumbs
Breadcrumbs can be effective way to navigate inside your workspace. They can help you switch between contexts and navigate hierarchical information.
Moving Information
The physical location of a node is important if you want to move a group of nodes to the different workspace. If notes live under a certain top-level node, it makes it easier to move them.
Think of templates: when you download a template, everything in that package within a single node. So you can move it with ease.
Operating multiple workspaces
With multiple workspaces you need to make sure that right information is accessible to the right people. This means being mindful about location of the nodes.
2 workspaces: referencing and moving nodes
Say you have 2 workspaces: personal (private) and team (shared). Remember: only nodes stored in shared workspaces are visible to team members. And only you can see nodes from your private workspace even if they are referenced in the shared one.
Usually you want to move the supertag with all the fields, right? If the field you are moving is not inside supertag, you risk fragmenting information across multiple workspaces.
And even when moved properly, 'Instance from supertag' fields might still reference their source workspace's supertag.
Deletion
You also need to consider how likely you are to delete a node (by mistake or intentionally). Because if you have nodes stored under the deleted node (in the fields or just indented), they will be deleted too.
When should you reuse fields?
Or, to be more precise:
Is it the best practice to reuse fields and share them between multiple supertags?
This question is also quite tricky.
In general, it is good practice to reuse fields when they:
- Serve exactly the same function
- Share identical settings/behaviors (visibility, AI commands, etc.)
Field reuse can help you avoid confusion and keep your workspace neat & tidy.
But there are exceptions.
As Dee Todd explained:
Let's take an example where you use status across your projects, book reads, and recipe completions. If you're doing a search for 'status: open,' you're going to get projects, recipes, and books... If you don't want that, then you need to use different fields for status.
Another thing you need to consider: field settings.
For example: in one supertag field needs to be always hidden, and in another hidden when empty. This is a good indicator that you need to use 2 different fields.
Inherited fields
When one supertag extends another, it inherits all the base suprtag's fields (and some settings).
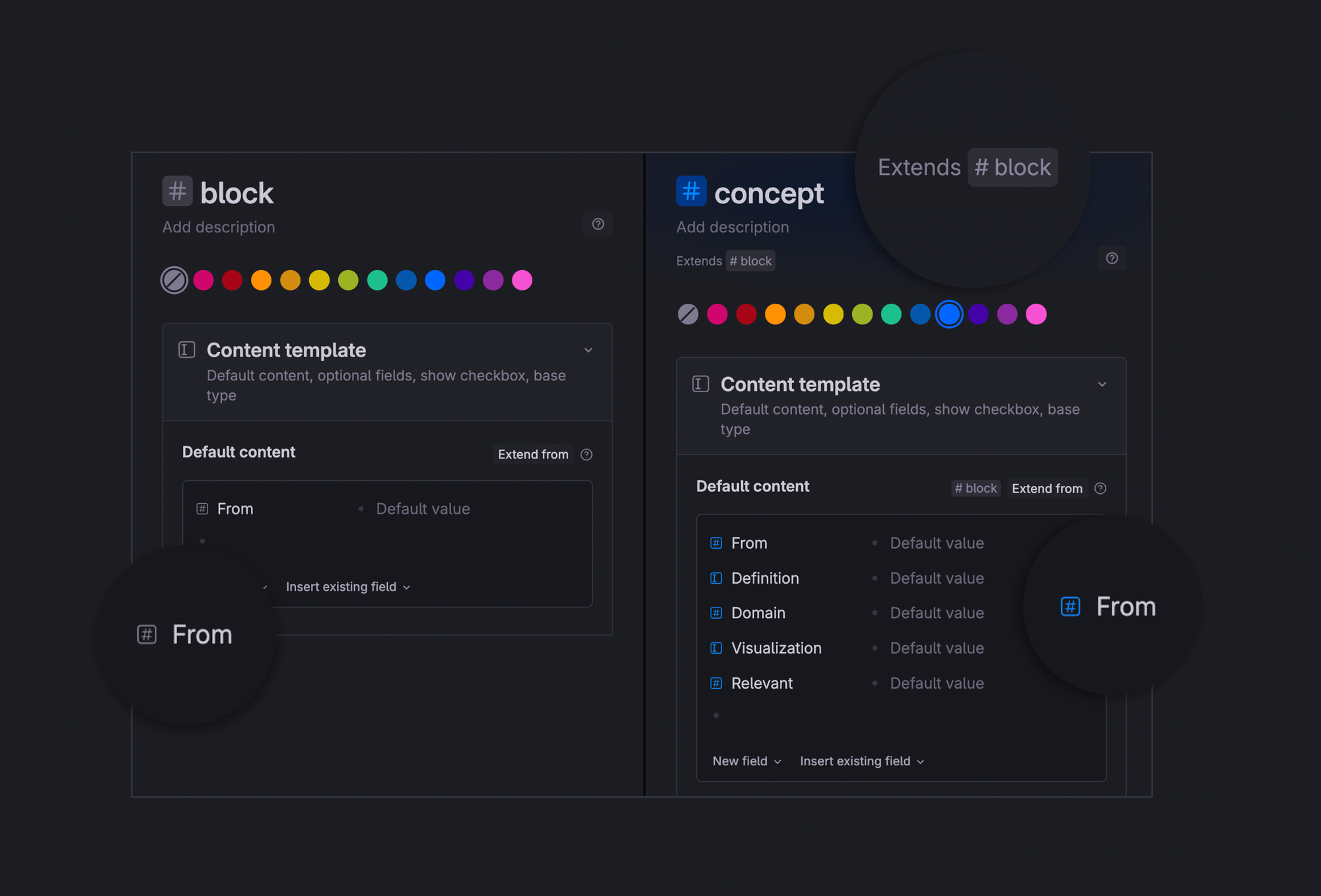
Inherited fields can be tricky. For example, you can not change the field's visibility or add commands. For that you must create a new field.
Yet you can change the default value for the inherited field. Default values are part of supertag's configuration, not the field's.
How can you effectively navigate the Tana schema?
We explored 2 themes here:
- How do I find all the fields/supertags
- How to deal with duplicates
Tana provides several powerful tools for schema management.
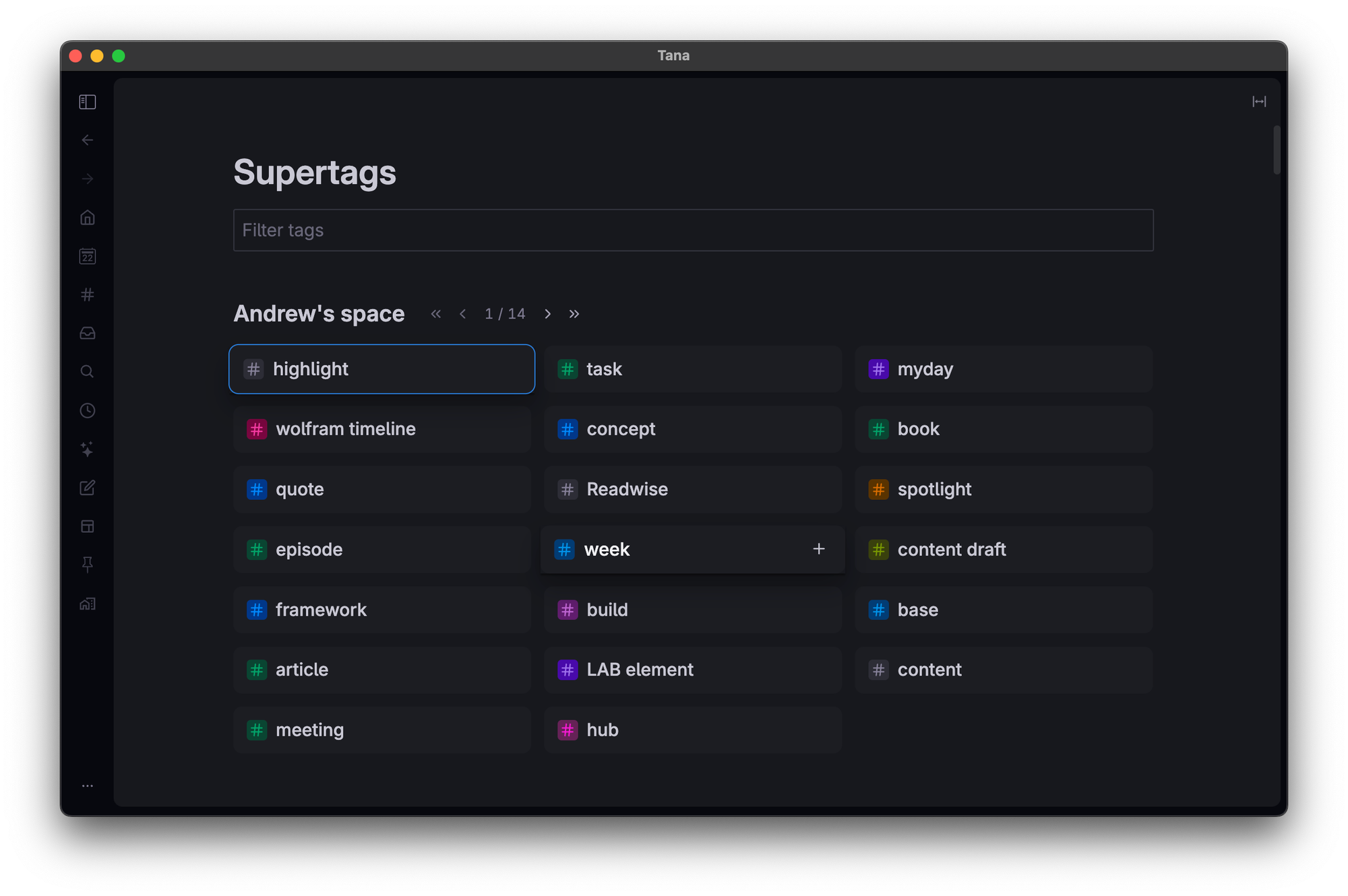
Supertags catalogue
Easiest way to see all your supertags.
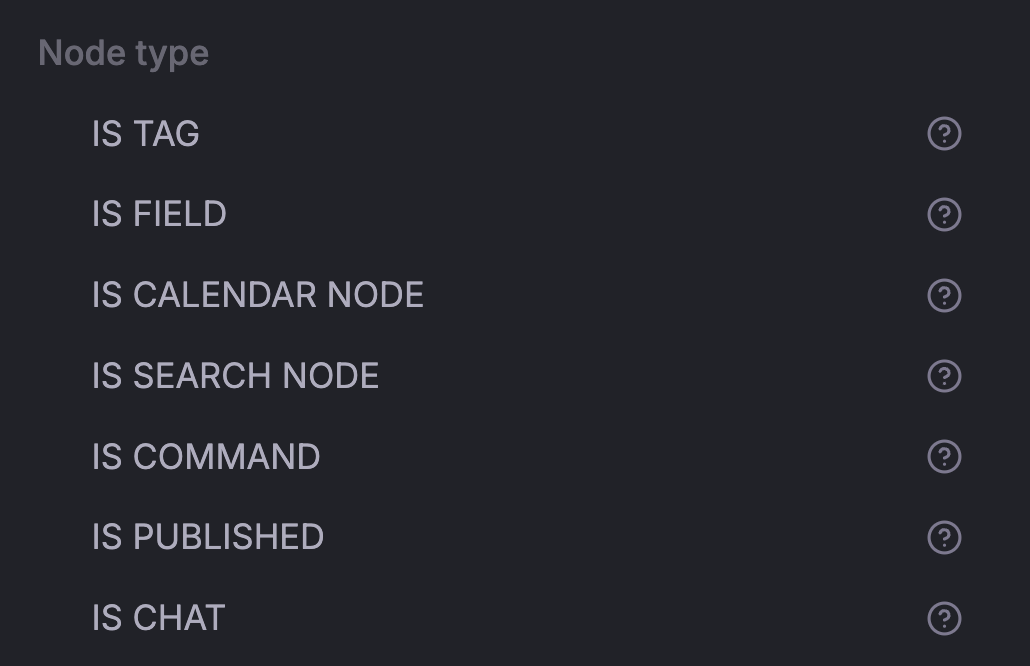
Search Operators
- Use IS TAG to find all supertags.
- Use IS FIELD to locate all fields.
When you query IS FIELD and apply the display path, you can see all the breadcrumbs for each field. This helps you understand the context and location of your fields.
How to see breadcrumps for multiple fields
Here are other search operators you can use:
Merging Duplicates
The search operators can help you find duplicates of supertags and fields. You can merge them just like you merge regular nodes. This way you will not lose any information, everything will go into the result of the merge.
Supertags hierarchy
If you use supertags extension → the system field "tags" helps you find all tags that are extended from a specific tag.
Use table view with the system field "tags" to see where tags are used and how they relate to each other.
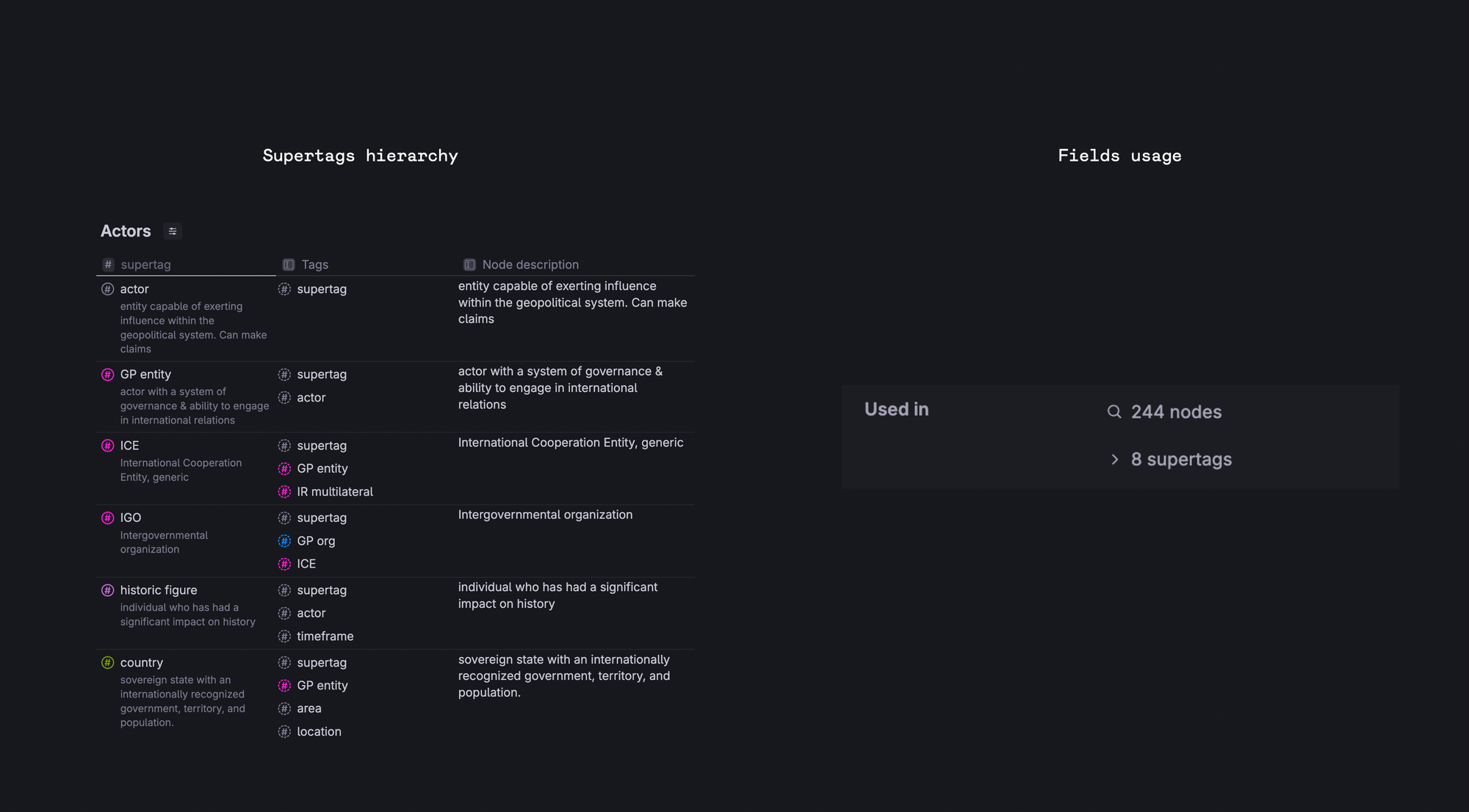
Field Usage
Want to know where a particular field is used in your schema? Go to the field configuration and scroll to the Field Usage section.
Wrapping Up
As you see, we covered a lot! For a deeper dive, check out the full recording here:
Tana JAM Recording
TO never miss our next JAM → join Tana Community (Slack) and subscribe to TanaStack